前言
TensorFlow使用GPU时默认占满所有可用GPU的显存,但只在第一个GPU上进行计算。如果不加以利用,另一块GPU就白白浪费了。因此如何有效提高GPU特别是TensorFlow上的利用率就成为了一项重要的考量。
简单的解决方案
一种经常提及的方法是设置可见的GPU,方法是通过设置CUDA_VISIBLE_DEVICES来完成,如果在shell中运行,每次运行某个shell脚本之前,加上exportCUDA_VISIBLE_DEVICES=0或者是你期望运行的GPU id(0到n-1,其中n是机器上GPU卡的数量),如果是在python脚本,还可以在所有代码之前加入如下代码:
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
另外为缓解TensorFlow一上来就占满整个GPU导致的问题,还可以在创建sess的时候传入附加的参数,更好的控制GPU的使用方法是:
config = tf.ConfigProto(allow_soft_placement=True,allow_grouth=True)
config.gpu_options.per_process_gpu_memory_fraction = 0.9 #占用90%显存
sess = tf.Session(config=config)
多GPU编程指南
上面的方法确实可以解决一定的问题,比如多个用户公用几块卡,每个人分配不同的卡来做实验,或者每张卡上运行不同的参数设置。但有时候我们更需要利用好已有的卡,来或得线性的加速比,以便在更短的时候获取参考结果,上面的方法就无能无力,只能自己写代码解决了。
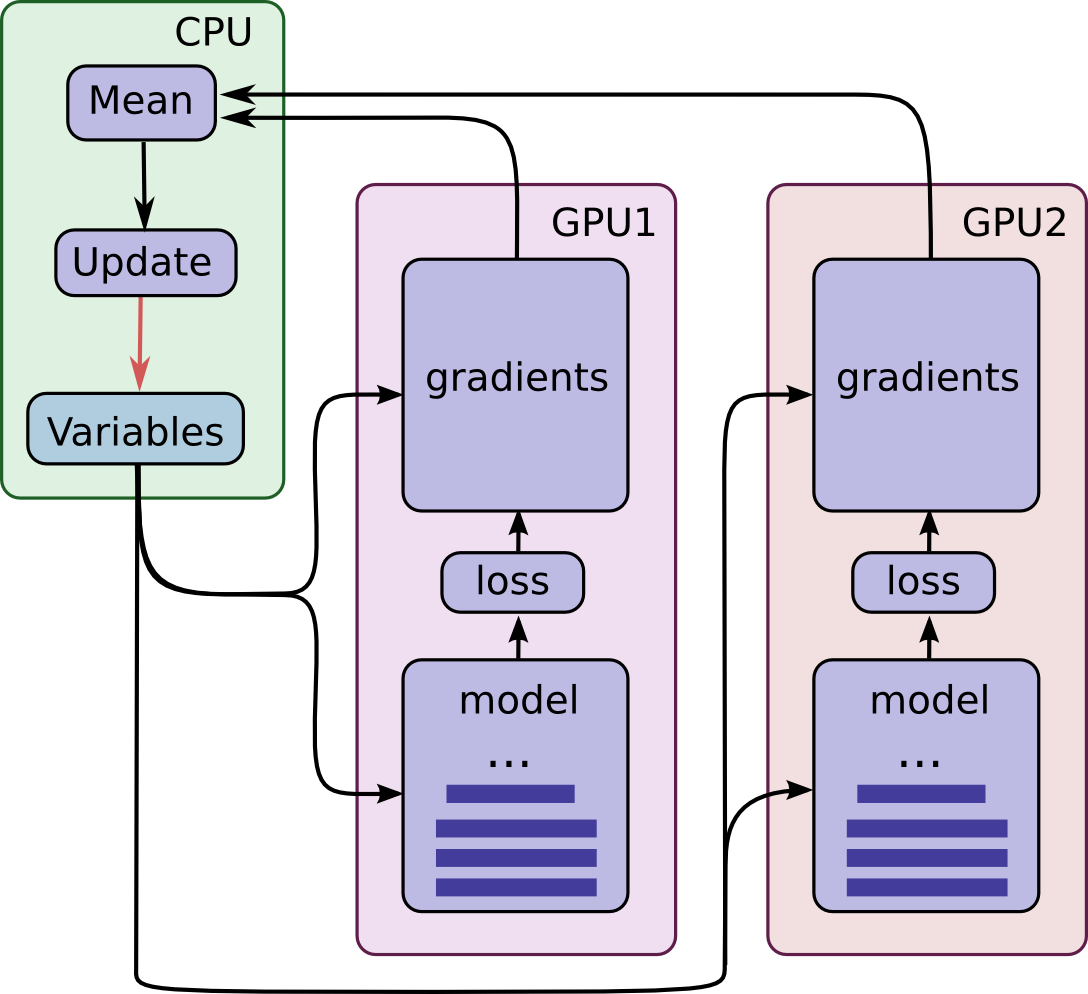
多GPU并行可分为模型并行和数据并行两大类,上图展示的是数据并行,这也是我们经常用到的方法,而其中数据并行又可分为同步方式和异步方式两种,由于我们一般都会配置同样的显卡,因此这儿也选择了同步方式,也就是把数据分给不同的卡,等所有的GPU都计算完梯度后进行平均,最后再更新梯度。
首先要改造的就是数据读取部分,由于现在我们有多快卡,每张卡要分到不同的数据,所以在获取batch的时候要把大小改为batch_x,batch_y=mnist.train.next_batch(batch_size*num_gpus),一次取足够的数据保证每块卡都分到batch_size大小的数据,然后我们对取到的数据进行切分,我们以i表示GPU的索引,连续的batch_size大小的数据分给同一块GPU:
_x=X[i*batch_size:(i+1)*batch_size]
_y=Y[i*batch_size:(i+1)*batch_size]
由于我们每个GPU都有图的一个副本,为了防止名字混乱,我们使用name_scope进行区分,也就是如下的形式;但是我们所有GPU上的图上的变量都是共享的,所以变量定义在CPU上,同时设置reuse为True(复用变量),来使得多个GPU共享变量。
for i in range(2):
with tf.device("/gpu:%d"%i):
with tf.name_scope("tower_%d"%i):
_x=X[i*batch_size:(i+1)*batch_size]
_y=Y[i*batch_size:(i+1)*batch_size]
logits=conv_net(_x,dropout,reuse_vars,True)