决策树
首先要介绍决策树的知识。之前已经有过相关的介绍。
Boosting
集成学习,由多个相关联的决策树联合决策。而且后面的决策树输入样本会与前面决策树的训练和预测相关。
XGBoost
1.怎么生成单个决策树。分裂点依据什么来划分;分裂后的结点预测值是多少。
停止分裂的条件:
- 当引入的分裂带来的增益小于一个阀值的时候,我们可以剪掉这个分裂,所以并不是每一次分裂loss function整体都会增加的,有点预剪枝的意思。
- 当树达到最大深度时则停止建立决策树,设置一个超参数max_depth,这个好理解吧,树太深很容易出现的情况学习局部样本,过拟合;
- (当样本权重和小于设定阈值时则停止建树,这个解释一下,涉及到一个超参数-最小的样本权重和min_child_weight,和GBM的min_child_leaf参数类似,但不完全一样,大意就是一个叶子节点样本太少了,也终止同样是过拟合;
2.多个决策树之间如何结合。
优化目标
- 在损失函数的基础上加入了正则项。
- 对目标函数进行二阶泰勒展开。
- 利用推导得到的表达式作为分裂准确,来构建每一颗树。
不同于传统的gbdt方式,只利用了一阶的导数信息(上篇GBDT推导过程Step3中Newton-Raphson会用到二阶信息,但一般实现中省略了Step3),xgboost对loss func做了二阶的泰勒展开,并在目标函数之外加入了正则项整体求最优解,用以 权衡目标函数的下降和模型的复杂程度,避免过拟合。具体推导详见陈天奇的ppt。
将目标函数做泰勒展开,并引入正则项:

正则化中的T表示叶子节点的个数,w表示节点的数值(这是回归树的东西,分类树对应的是类别)。直观上看,目标要求预测误差尽量小,叶子节点尽量少,节点数值尽量不极端。
除去常数项,求得每个样本的一阶导g_i 和二阶导h_i,将目标函数按叶子节点规约分组,略去一些中间步骤:
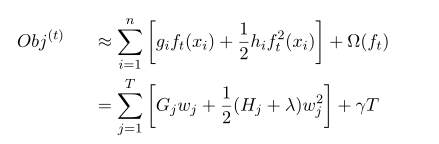
在树结构是fix的时候,上式中叶子节点权重w_j有闭式解,解和对应的目标函数值如下:
说明:w是最优化求出来的,不是啥平均值或规则指定的。
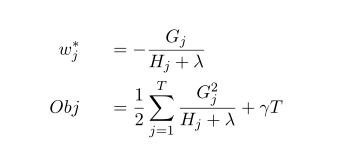
在目标函数是LogLoss损失函数下,这里给出一阶导g_i和二阶导h_i的推导:


并行化
支持并行化,直接的效果是训练速度快,boosting技术中下一棵树依赖上述树的训练和预测,所以树与树之间应该是只能串行!那么可以并行的地方在哪里呢?
在选择最佳分裂点,进行枚举的时候并行!(据说恰好这个也是树形成最耗时的阶段)具体的对于某个节点,节点内选择最佳分裂点,候选分裂点计算增益用多线程并行。
Weighted Quantile Sketch
较少的离散值作为分割点倒是很简单,比如“是否是单身”来分裂节点计算增益是很简单,但是“月收入”这种feature,取值很多,从5k~50k都有,总不可能每个分割点都来试一下计算分裂增益吧?(比如月收入feature有1000个取值,难道你把这1000个用作分割候选?缺点1:计算量很大;缺点2:出现叶子节点样本过少,过拟合)。我们常用的习惯就是划分区间,那么问题来了,这个区间分割点如何确定(难道平均分割)?
大家还记得每个样本在节点(将要分裂的节点)处的loss function一阶导数gi和二阶导数hi,衡量预测值变化带来的loss function变化,举例来说,将样本“月收入”进行升序排列,5k、5.2k、5.3k、…、52k,分割线为“收入1”、“收入2”、…、“收入j”,满足(每个间隔的样本的hi之和/总样本的hi之和)为某个百分比ϵ(我这个是近似的说法),那么可以一共分成大约1/ϵ个分裂点。

而且,有适用于分布式的算法设计。
针对稀疏数据的算法
XGBoost还特别设计了针对稀疏数据的算法。假设样本的第i个特征缺失时,无法利用该特征对样本进行划分,这里的做法是将该样本默认地分到指定的子节点,至于具体地分到哪个节点还需要某算法来计算。
算法的主要思想是,分别假设特征缺失的样本属于右子树和左子树,而且只在不缺失的样本上迭代,分别计算缺失样本属于右子树和左子树的增益,选择增益最大的方向为缺失数据的默认方向。
后剪枝
交叉验证
方便选择最好的参数,early stop,比如你发现30棵树预测已经很好了,不用进一步学习残差了,那么停止建树。
行采样、列采样
随机森林的套路(防止过拟合)。
Shrinkage
你可以是几个回归树的叶子节点之和为预测值,也可以是加权,比如第一棵树预测值为3.3,label为4.0,第二棵树才学0.7,这样再后面的树还学个鬼,所以给他打个折扣,比如3折,那么第二棵树训练的残差为4.0-3.3*0.3=3.01,这就可以发挥了啦,以此类推,作用是啥,防止过拟合,如果对于“伪残差”学习,那更像梯度下降里面的学习率。
设置样本权重
XGBoost还支持设置样本权重,这个权重体现在梯度g和二阶梯度h上,是不是有点adaboost的意思,重点关注某些样本。
Column Block for Parallel Learning - 工程优化
总的来说:按列切开,升序存放。
这样方便并行,同时解决一次性样本读入炸内存的情况。
由于将数据按列存储,可以同时访问所有列,那么可以对所有属性同时执行split finding算法,从而并行化split finding(切分点寻找)。特征间并行。
可以用多个block(Multiple blocks)分别存储不同的样本集,多个block可以并行计算。特征内并行。
Blocks for Out-of-core Computation - 工程优化
数据大时分成多个block存在磁盘上,在计算过程中,用另外的线程读取数据,但是由于磁盘IO速度太慢,通常更不上计算的速度,将block按列压缩,对于行索引,只保存第一个索引值,然后只保存该数据与第一个索引值之差(offset),一共用16个bits来保存offset。因此,一个block一般有2的16次方个样本。
调参
General parameters:
- booster: [default=gbtree]
Parameters for Tree Booster:
- eta: [default=0.3, alias: learning_rate]. shrinkage参数,用于更新叶子节点权重时,乘以该系数,避免步长过大。参数值越大,越可能无法收敛。把学习率eta设置的小一些,小学习率可以使得后面的学习更加仔细。值越小越保守。
- gamma: [default=0, alias: min_split_loss]. 分裂条件。range: [0,∞]. 值越大越保守。
- max_depth: [default=6]. gbdt每颗树的最大深度,树高越深,越容易过拟合。
- min_child_weight: [default=1]. 是每个叶子里面h的和至少是多少,对正负样本不均衡时的0-1分类而言,假设h在0.01附近,min_child_weight为1意味着叶子节点中最少需要包含100个样本。这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易overfitting。值越大越保守。
- max_delta_step: 如果设立了该值,对叶子节点的权重值做了约束在[max_delta_step, max_delta_step]。以防在某些loss下权重值过大,默认是0(其实代表inf)。可以试试把这个参数设置到1-10之间的一个值。这样会防止做太大的更新步子,使得更新更加平缓。Usually this parameter is not needed, but it might help in logistic regression when class is extremely imbalanced. Set it to value of 1-10 might help control the update.
- subsample
- colsample_bytree
- lambda: 控制模型复杂程度的权重值的L2正则项参数,参数值越大,模型越不容易overfitting。值越大模型越保守。
- alpha: 控制模型复杂程度的权重值的L1正则项参数,参数值越大,模型越不容易overfitting。值越大模型越保守。
- scale_pos_weight: 如果优化的是仅仅展示排序,就是AUC的话,可以采用平衡正负样本权重的办法调大正样本权重。设置scale_pos_weight就可以把正样本权重乘这个系数。如果还需要优化回归的性能,还需要在此基础上做下recalibration。
Parameters for Linear Booster:
- lambda
- alpha
Learning Task parameters:
- objective:binary:logistic、multi:softmax、multi:softprob、default=reg:linear。
- eval_metric:The metric to be used for validation data。The default values are rmse for regression and error for classification。
- seed: random number seed. 可以用于产生可重复的结果(每次取一样的seed即可得到相同的随机划分)。
Command Line Parameters:
- num_round: gbdt的棵数,棵数越多,训练误差越小,但是棵数过多容易过拟合。需要同时观察训练 loss和测试loss,确定最佳的棵数。
- data: The path of training data.
- test:data: The path of test data to do prediction.
- save_period: [default=0]. the period to save the model.
- task: [default=train]. options: train, pred, eval, dump.
- model_in: [default=NULL]. path to input model, needed for test, eval, dump, if it is specified in training, xgboost will continue training from the input model.
- model_out: [default=NULL]. path to output model after training finishes, if not specified, will output like 0003.model where 0003 is number of rounds to do boosting.
- model_dir: [default=models]. The output directory of the saved models during training.
Control Overfitting:
- The first way is to directly control model complexity: max_depth, min_child_weight, gamma.
- The second way is to add randomness to make training robust to noise: subsample, colsample_bytree.
- You can also reduce stepsize eta, but needs to remember to increase num_round when you do so.
Handle Imbalanced Dataset:
- If you care only about the ranking order (AUC) of your prediction. Balance the positive and negative weights, via scale_pos_weight; Use AUC for evaluation.
- If you care about predicting the right probability. In such a case, you cannot re-balance the dataset; In such a case, set parameter max_delta_step to a finite number (say 1) will help convergence.
机器学习系列(12)_XGBoost参数调优完全指南(附Python代码)
机器学习系列(12)_XGBoost参数调优完全指南(附Python代码)
Complete Guide to Parameter Tuning in XGBoost (with codes in Python)
初始参数:
- 初始学习速率0.1和tree_based参数调优的估计器数目100给其他参数一个初始值。
- max_depth = 5:默认6,树的最大深度,这个参数的取值最好在3-10之间。
- min_child_weight = 1:默认是1决定最小叶子节点样本权重和。如果是一个极不平衡的分类问题,某些叶子节点下的值会比较小,这个值取小点。
- gamma = 0:默认0,在0.1到0.2之间就可以。树的叶子节点上作进一步分裂所需的最小损失减少。这个参数后继也是要调整的。
- subsample, colsample_bytree = 0.8:样本采样、列采样。典型值的范围在0.5-0.9之间。
- scale_pos_weight = 1:默认1,如果类别十分不平衡取较大正值。
调整’n_estimators’:[100,200,500,1000,1500]。再确定了其他参数之后,可以用XGBoost中的cv函数来确定最佳的决策树数量。函数在下一节。
调整max_depth和min_weight。max_depth和min_weight它们对最终结果有很大的影响。得到最优值后,可以在最优值附近进一步调整,来找出理想值。我们把上下范围各拓展1,因为之前我们进行组合的时候,参数调整的步长是2。
- max_depth:range(3,10,2)=[3, 5, 7, 9]。
- min_weight:range(1,6,2)=[1, 3, 5]。
调整gamma参数。
- ‘gamma’:[i/10.0 for i in range(0,7)]=[0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6]。
调整’n_estimators’,用XGBoost中的cv函数来确定最佳的决策树数量。
调整subsample和colsample_bytree参数。得到最优值后,调整步长为0.05,在最优值附近继续优化。
- ‘subsample’:[i/10.0 for i in range(6,10)]=[0.6, 0.7, 0.8, 0.9]。
- ‘colsample_bytree’:[i/10.0 for i in range(6,10)]=[0.6, 0.7, 0.8, 0.9]。
调整正则化参数。一个一个调,先粗调,再细调。
- ‘reg_alpha’:[1e-5, 1e-2, 0.1, 1, 100]=[1e-05, 0.01, 0.1, 1, 100] 默认0 L1正则项参数,参数值越大,模型越不容易过拟合。
- ‘reg_lambda’:[1,5,10,50] 默认1 L2正则项参数,参数值越大,模型越不容易过拟合。
进一步降低学习速率,增加更多的树。
- ‘learning_rate’:[0.01,0.1,0.3]。
- ‘n_estimators’:[1000,1200,1500,2000,2500]。确定学习率之后,可以用XGBoost中的cv函数来确定最佳的决策树数量,就不用搜索了。
用XGBoost中的cv函数来确定最佳的决策树数量
机器学习系列(12)_XGBoost参数调优完全指南(附Python代码)
def modelfit(alg, dtrain, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='auc', early_stopping_rounds=early_stopping_rounds, show_progress=False)
alg.set_params(n_estimators=cvresult.shape[0])
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain['Disbursed'],eval_metric='auc')
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#Print model report:
print "\nModel Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob)
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
自定义XGBoost参数搜索函数
为什么要自定义?因为在XGBoost直接调用sklearn的grid search函数时,没有办法使用early stop。使用early stop很有帮助,一方面能够避免过拟合,另一方面能够节省不少时间,所以可以直接写个函数替代grid search。下面代码中实现是逐个参数搜寻,逐个找到最优参数,实际上没有grid search,但是效果一般不会太差,而且省下很多时间。
def model_fit(params, dtrain, max_round=300, cv_folds=5, n_stop_round=50):
"""
对一组参数进行交叉验证,并返回最优迭代次数和最优的结果。
Args:
params: dict, xgb 模型参数。
见 xgb_grid_search_cv 函数
Returns:
n_round: 最优迭代次数
mean_auc: 最优的结果
"""
cv_result = xgb.cv(params, dtrain, max_round, nfold=cv_folds,
metrics='auc', early_stopping_rounds=n_stop_round, show_stdv=False)
n_round = cv_result.shape[0] # 最优模型,最优迭代次数
mean_auc = cv_result['test-auc-mean'].values[-1] # 最好的AUC
return n_round, mean_auc
def xgb_grid_search_cv(params, key, search_params, dtrain, max_round=300, cv_folds=5, n_stop_round=50, return_best_model=True, verbose=True):
"""
自定义 grid_search_cv for xgboost 函数。
Args:
params: dict, xgb 模型参数。
key: 待搜寻的参数。
search_params:list, 待搜寻的参数list。
dtrain: 训练数据
max_round: 最多迭代次数
cv_folds: 交叉验证的折数
early_stopping_rounds: 迭代多少次没有提高则停止。
return_best_model: if True, 在整个训练集上使用最优的参数训练模型。
verbose:if True, 打印训练过程。
Returns:
cv_results: dict,所有参数组交叉验证的结果。
- mean_aucs: 每组参数对应的结果。
- n_rounds: 每组参数最优迭代轮数。
- list_params: 搜寻的每一组参数。
- best_mean_auc: 最优的结果。
- best_round: 最优迭代轮数。
- best_params: 最优的一组参数。
best_model: XGBoostClassifer()
"""
import time
mean_aucs = list()
n_rounds = list()
list_params = list()
print('Searching parameters: %s %s' % (key, str(values)))
tic = time.time()
for search_param in search_params:
params[key] = search_param
list_params.append(params.copy())
n_round, mean_auc = model_fit(params, dtrain, max_round, cv_folds, n_stop_round)
if verbose:
print('%s=%s: n_round=%d, mean_auc=%g. Time cost %gs' % (key, str(search_param), n_round, mean_auc, time.time() - tic))
mean_aucs.append(mean_auc)
n_rounds.append(n_round)
best_mean_auc = max(mean_aucs)
best_index = mean_aucs.index(best_mean_auc) # 最优的一组
best_round = n_rounds[best_index]
best_params = list_params[best_index]
cv_result = {'mean_aucs': mean_aucs, 'n_rounds': n_rounds, 'list_params': list_params, 'best_mean_auc': best_mean_auc, 'best_round': best_round, 'best_params': best_params}
if return_best_model:
best_model = xgb.train(best_params, dtrain, num_boost_round=best_round)
else:
best_model = None
if verbose:
print('best_mean_auc = %g' % best_mean_auc)
print('best_round = %d' % best_round)
print('best_params = %s' % str(best_params))
return cv_result, best_model
XGBoost的Python接口
XGBoost的label必须从0开始编码。
自带接口
import xgboost as xgb
params={
'eta': 0.3,
'max_depth':3,
'min_child_weight':1,
'gamma':0.3,
'subsample':0.8,
'colsample_bytree':0.8,
'booster':'gbtree',
'objective': 'binary:logistic',
'nthread':12,
'scale_pos_weight': 1,
'lambda':1,
'seed':27,
'silent':0 ,
'eval_metric': 'auc'
}
d_train = xgb.DMatrix(X_train, label=y_train)
d_valid = xgb.DMatrix(X_test, label=y_test)
d_test = xgb.DMatrix(X_test)
watchlist = [(d_train, 'train'), (d_valid, 'valid')]
model_bst = xgb.train(params, d_train, 30, watchlist, early_stopping_rounds=500, verbose_eval=10)
y_bst= model_bst.predict(d_test)
print("XGBoost_自带接口 AUC Score : %f" % metrics.roc_auc_score(y_test, y_bst))
XGBoost自带接口生成的新特征
train_new_feature= model_bst.predict(d_train, pred_leaf=True)
test_new_feature= model_bst.predict(d_test, pred_leaf=True)
train_new_feature1 = DataFrame(train_new_feature)
test_new_feature1 = DataFrame(test_new_feature)
print("新的特征集(自带接口):",train_new_feature1.shape)
print("新的测试集(自带接口):",test_new_feature1.shape)
有一个cv函数,cv函数仅用于确定n_estimators,而其他参数不能使用此确定。它给出对应于一组其他参数的最佳n_estimators值。
model_fit(params, dtrain, max_round=300, cv_folds=5, n_stop_round=50)函数:
cv_result = xgb.cv(params, dtrain, max_round, nfold=cv_folds, metrics='auc', early_stopping_rounds=n_stop_round, show_stdv=False)
n_round = cv_result.shape[0] # 最优模型,最优迭代次数
mean_auc = cv_result['test-auc-mean'].values[-1] # 最好的AUC
xgboost中dump_model语句中feature map file如何生成?
Scikit-Learn接口
from xgboost.sklearn import XGBClassifier
clf = XGBClassifier(
n_estimators=30,#三十棵树
learning_rate =0.3,
max_depth=3,
min_child_weight=1,
gamma=0.3,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=12,
scale_pos_weight=1,
reg_lambda=1,
seed=27)
model_sklearn=clf.fit(X_train, y_train)
y_sklearn= clf.predict_proba(X_test)[:,1]
clf.predict接口也存在!!!
print("XGBoost_sklearn接口 AUC Score : %f" % metrics.roc_auc_score(y_test, y_sklearn))
sklearn接口生成的新特征
train_new_feature= clf.apply(X_train)#每个样本在每颗树叶子节点的索引值
test_new_feature= clf.apply(X_test)
train_new_feature2 = DataFrame(train_new_feature)
test_new_feature2 = DataFrame(test_new_feature)
print("新的特征集(sklearn接口):",train_new_feature2.shape)
print("新的测试集(sklearn接口):",test_new_feature2.shape)
如何获得每个样本在训练后树模型每棵树的哪个叶子结点上?
new_feature = bst.predict(d_test, pred_leaf=True)即可得到一个(nsample, ntrees)的结果矩阵,即每个样本在每个树上的leaf_Index。(设置pre_leaf=True)
与GDBT、深度学习的对比
XGBoost第一感觉就是防止过拟合+各种支持分布式/并行,所以一般传言这种大杀器效果好(集成学习的高配)+训练效率高(分布式),与深度学习相比,对样本量和特征数据类型要求没那么苛刻,适用范围广。
GBDT有两种描述版本:
- 把GBDT说成一个迭代残差树,认为每一棵迭代树都在学习前N-1棵树的残差;
- 把GBDT说成一个梯度迭代树,使用梯度迭代下降法求解,认为每一棵迭代树都在学习前N-1棵树的梯度下降值。
有说法说前者是后者在loss function为平方误差下的特殊情况。这里说下我的理解,仍然举个例子:第一棵树形成之后,有预测值ŷi,真实值(label)为yi,前者版本表示下一棵回归树根据样本(xi,yi−ŷi)进行学习,后者的意思是计算loss function在第一棵树预测值附近的梯度负值作为新的label,也就是对应XGBoost中的−gi。
这里真心有个疑问:
XGBoost在下一棵树拟合的是残差还是负梯度,还是说是一阶导数+二阶导数,−gi(1+hi)?换句话说GBDT残差树群有一种拟合的(输入样本)是(xi,yi−ŷi),还一种拟合的是(xi,−gi),XGBoost呢?
XGBoost和深度学习的关系,陈天奇在Quora上的解答如下:
不同的机器学习模型适用于不同类型的任务。深度神经网络通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据。而基于树模型的XGBoost则能很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。这两类模型都很重要,并广泛用于数据科学竞赛和工业界。举例来说,几乎所有采用机器学习技术的公司都在使用tree boosting,同时XGBoost已经给业界带来了很大的影响。
区别:
- 传统GBDT以CART作为基分类器,XGBoost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- XGBoost和GBDT的一个区别在于目标函数上。在XGBoost中,损失函数+正则项。GBDT中,只有损失函数。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。正则化包括了两个部分,都是为了防止过拟合,剪枝是都有的,叶子结点输出L2平滑是新增的。
- XGBoost中利用二阶导数的信息,而GBDT只利用了一阶导数。同时XGBoost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- XGBoost在建树的时候利用的准则来源于目标函数推导,而GBDT建树利用的是启发式准则。(这一点,我个人认为是xgboost牛B的所在,也是为啥要费劲二阶泰勒展开)
- XGBoost中可以自动处理空缺值,自动学习空缺值的分裂方向,GBDT(sklearn版本)不允许包含空缺值。
- XGBoost加入了列采样。
- XGBoost通过预排序的方法来实现特征并行,提高模型训练效率。
- XGBoost支持分布式计算。
- 其他若干工程实现上的不同。
联系:
- XGBoost和GBDT的学习过程都是一样的,都是基于Boosting的思想,先学习前n-1个学习器,然后基于前n-1个学习器学习第n个学习器。(Boosting)
- 建树过程都利用了损失函数的导数信息(Gradient),只是大家利用的方式不一样而已。
- 都使用了学习率来进行Shrinkage,从前面我们能看到不管是GBDT还是XGBoost,我们都会利用学习率对拟合结果做缩减以减少过拟合的风险.
参考
机器学习算法中 GBDT 和 XGBOOST 的区别有哪些?(好文)
XGBoost Plotting API以及GBDT组合特征实践(编程实战)
XGBoost Plotting API以及GBDT组合特征实践(文中并没有对新构造的特征进行0/1编码,因为文中是将新特征用于树模型;如果要将新特征用于LR或者FM等模型,要进行0/1编码。)
xgboost cross_validation&自定义目标函数和评价函数&base_score参数