GBDT理论推导
GBDT模型全称Gradient Boosted Decision Trees,在1999年由Jerome Friedman提出,将GBDT模型应用于ctr预估,最早见于yahoo。
GBDT是一个加性回归模型,通过boosting迭代的构造一组弱学习器,相对LR的优势如不需要做特征的归一化,自动进行特征选择,模型可解释性较好,可以适应多种损失函数如SquareLoss,LogLoss等。但作为非线性模型,其相对线性模型的缺点也是显然的:boosting是个串行的过程,不能并行化,计算复杂度较高,同时其不太适合高维稀疏特征,通常采用稠密的数值特征如点击率预估中的COEC。
GBDT模型在采用LogLoss时推导较逻辑回归复杂一些,我们这里给出具体原理和推导细节。我们的目标是寻找使得期望损失最小的决策函数,我们要求其具有一定的形式:即是一组弱学习器的加性组合。
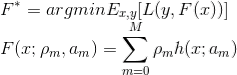
我们可以在函数空间上形式的使用梯度下降法求解,首先固定x,对F(x)求解其最优解。这里给出框架流程和LogLoss下的推导。
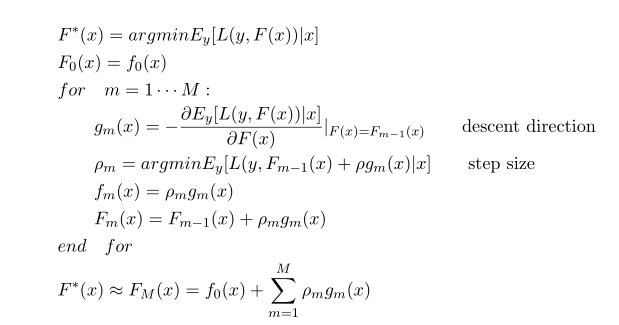
LogLoss损失函数:
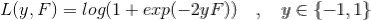
Step1.求解初始F_0。令其偏导为0:
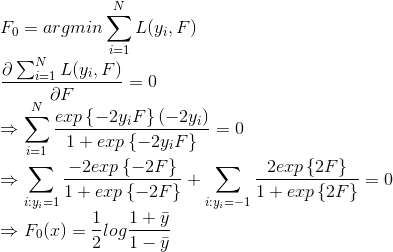
Step2.估计g_m(x),并用决策树对其进行拟合。
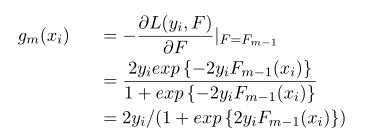
Step3.用a single Newton-Raphson step 去近似求解下降方向步长,通常的实现中Step3被省略,采用shrinkage的策略通过参数设置步长,避免过拟合。
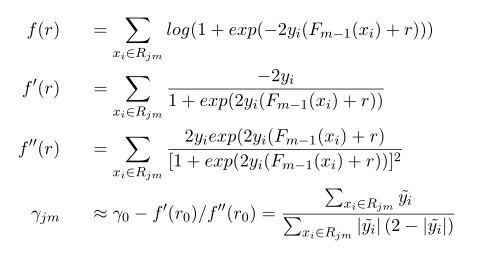
调参
我们把重要参数分为两类,第一类是Boosting框架的重要参数,第二类是弱学习器即CART回归树的重要参数。
调参顺序:Learning-rate+n_estimators—-> max_deep+min_samples_split—> min_samples_split+min_samples_leaf—-> max_feature—> subsample—-> learning_rate/2+n_estimators*2
GBDT类库boosting框架参数
- n_estimators:弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
- learning_rate:即每个弱学习器的权重缩减系数ν,也称作步长。
- init:即我们的初始化的时候的弱学习器,拟合对应原理篇里面的f0(x),如果不输入,则用训练集样本来做样本集的初始化分类回归预测。否则用init参数提供的学习器做初始化分类回归预测。一般用在我们对数据有先验知识,或者之前做过一些拟合的时候,如果没有的话就不用管这个参数了。
- loss:即我们GBDT算法中的损失函数。分类模型和回归模型的损失函数是不一样的。对于分类模型,有对数似然损失函数”deviance”和指数损失函数”exponential”两者输入选择。默认是对数似然损失函数”deviance”。一般来说,推荐使用默认的”deviance”。它对二元分离和多元分类各自都有比较好的优化。而指数损失函数等于把我们带到了Adaboost算法。对于回归模型,有均方差”ls”, 绝对损失”lad”, Huber损失”huber”和分位数损失“quantile”。默认是均方差”ls”。一般来说,如果数据的噪音点不多,用默认的均方差”ls”比较好。如果是噪音点较多,则推荐用抗噪音的损失函数”huber”。而如果我们需要对训练集进行分段预测的时候,则采用“quantile”。
- alpha:这个参数只有GradientBoostingRegressor有,当我们使用Huber损失”huber”和分位数损失“quantile”时,需要指定分位数的值。默认是0.9,如果噪音点较多,可以适当降低这个分位数的值。
GBDT类库弱学习器参数
- max_feature:划分时考虑的最大特征数。
- max_depth:决策树最大深度。
- min_samples_split:内部节点再划分所需最小样本数。
- min_samples_leaf:叶子节点最少样本数。
- min_weight_fraction_leaf:叶子节点最小的样本权重和。
- max_leaf_nodes:最大叶子节点数。
- min_impurity_split:节点划分最小不纯度。
利用GBDT模型构造新特征
先用已有特征训练GBDT模型,然后利用GBDT模型学习到的树来构造新特征,最后把这些新特征加入原有特征一起训练模型。构造的新特征向量是取值0/1的,向量的每个元素对应于GBDT模型中树的叶子结点。当一个样本点通过某棵树最终落在这棵树的一个叶子结点上,那么在新特征向量中这个叶子结点对应的元素值为1,而这棵树的其他叶子结点对应的元素值为0。新特征向量的长度等于GBDT模型里所有树包含的叶子结点数之和。
可以使用sklearn的apply()接口,也可以使用xgboost原生接口,new_feature = bst.predict(X_test, pred_leaf=True)即可得到一个(nsample, ntrees)的结果矩阵。
X_train_1用于生成模型 X_train_2用于生成组合特征,这样的话就得用一部分数据来训练生成模型了。用于生成模型和用于生成组合特征的数据可不可以是同一份数据?
数据最好不要重合,不然容易过拟合。
from xgboost.sklearn import XGBClassifier
clf = XGBClassifier(
learning_rate =0.2, #默认0.3
n_estimators=200, #树的个数
max_depth=8,
min_child_weight=10,
gamma=0.5,
subsample=0.75,
colsample_bytree=0.75,
objective= 'binary:logistic', #逻辑回归损失函数
nthread=8, #cpu线程数
scale_pos_weight=1,
reg_alpha=1e-05,
reg_lambda=10,
seed=1024) #随机种子
# 预测
clf.fit(X_train_1, y_train_1)
# 生成我们需要的one hot特征
new_feature= clf.apply(X_train_2)