图模型
图模型是多变量的概率分布中的表示和推理的强大框架,它已经被证明在随机建模的不同领域有很大的用处,例如计算机视觉、知识表示、贝叶斯统计和自然语言处理。
基于很多变量的分布的表示是非常昂贵的。例如,n个二进制变量的联合概率表需要存储2的n次方复杂度的浮点数。图形建模中,非常多的变量分布可以表示为局部函数的乘积,这些局部函数依赖于变量的很小的子集。这种分解结果与变量之间的某些条件独立关系密切相关。这些信息都可以通过图形和轻松汇总。
实际上,因子分解、条件独立性和图结构之间的关系构成了图模型框架的许多功能:条件独立性观点对于设计模型非常有用,分解观点对于设计推理算法非常有用。
概率图模型中,数据样本由公式G = (V, E)建模表示。
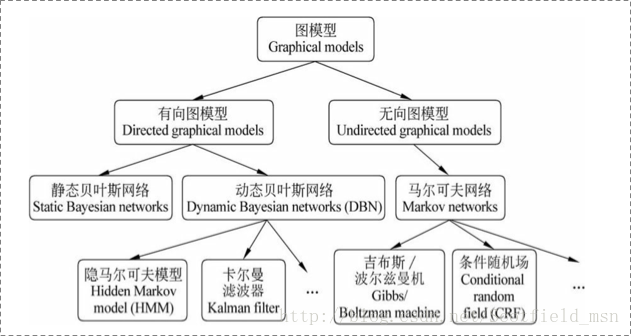
其中V表示节点,即随机变量。E表示边,即随机变量之间的概率关系。
贝叶斯网络是有向的,马尔可夫网络无向。所以,贝叶斯网络适合有单向依赖的数据建模,马尔科夫网络适合实体之间互相依赖的建模。具体来说,他们之间的核心差异在于如何求P = (Y),即怎么表示Y = (y1, ……, yn)这个联合概率,其中Y表示一批随机变量,P(Y)为这些随机变量的分布。有向图直接是概率的乘积,生成式模型;无向图是判别式模型。
一个图模型,主要有三个主要的关注点:
- 1)图模型的表示(representation);指的是一个图模型应该是什么样子的。
- 2)图模型的推断(inference);指的是已知图模型的情况下,怎么去计算一个查询的概率,例如已经一些观察节点,去求其它未知节点的概率。
- 3)图模型的学习(learning);这里又分为两类,一类是图的结构学习;一类是图的参数学习。
无向图
分为马尔可夫网络,马尔可夫网络分为吉布斯/波尔兹曼机和条件随机场。
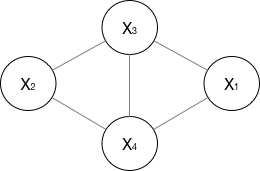
如果一个graph太大,可以用因子分解将P=(Y)写为若干个联合概率的乘积。即将一个图分为若干个“小团”,注意每个团必须是“最大团”。
P(Y)=\frac{1}{Z(x)} \prod_{c}\psi_{c}(Y_{c} ),其中Z(x) = \sum_{Y} \prod_{c}\psi_{c}(Y_{c} )
其中,\psi_{c}(Y_{c} )是一个最大团C上随机变量们的联合概率,一般取指数函数:
| \psi_{c}(Y_{c} ) = e^{-E(Y_{c})} =e^{\sum_{k}\lambda_{k}f_{k}(c,y | c,x)} |
以上为势函数,那么概率无向图的联合概率分布可以在因子分解下表示为:
| P(Y )=\frac{1}{Z(x)} \prod_{c}\psi_{c}(Y_{c} ) = \frac{1}{Z(x)} \prod_{c} e^{\sum_{k}\lambda_{k}f_{k}(c,y | c,x)} = \frac{1}{Z(x)} e^{\sum_{c}\sum_{k}\lambda_{k}f_{k}(y_{i},y_{i-1},x,i)} |
无向图也可以建立生成式模型,例如马尔可夫随机场。
有向图
分为静态贝叶斯网络和动态贝叶斯网络,动态贝叶斯网络分为隐马尔可夫模型和卡尔曼滤波器。
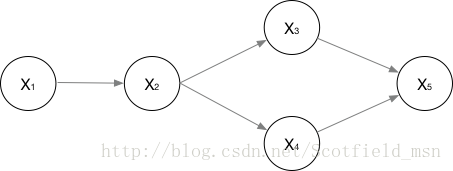
| 联合概率为:P(x_{1}, {\cdots}, x_{n} )=\prod_{i=0}P(x_{i} | \pi(x_{i})) |
注:贝叶斯网络结构有效地表达了属性间的条件独立性,给定父结点集,贝叶斯网络假设每个属性与它的非后裔属性独立,故联合概率如上所示。摘自西瓜书157页。
贝叶斯网络的动态贝叶斯网络和静态贝叶斯网络并不是说网络结构随着时间的变化而发生变化,而是样本数据,或者说观测数据,随着时间的变化而变化。
隐马尔可夫模型HMM - 生成式模型
NLP —— 图模型(一)隐马尔可夫模型(Hidden Markov model,HMM)
隐马尔可夫模型的三个问题
- 给定模型,如何有效计算其产生观测序列的概率。
- 给定模型和观测序列,如何找到与此观测序列最匹配的状态序列。
- 给定观测序列,如何调整模型参数使得观测序列出现的概率最大。
序列概率过程(计算问题)
对一条序列计算其整体的概率。
- 直接计算法(穷举搜索):计算量太大,复杂度O(T*N^T)
- 前向算法:初始化前向变量,逐步向后计算,复杂度O(TNN)
- 后向算法:初始化后向变量,逐步向前计算,复杂度O(TNN)
序列标注过程(解码问题)
CRF的序列标注问题中,我们要计算的是条件概率。
- 近似算法,每个时刻t均选择使当前时刻下概率最大的状态,组成一个状态序列。但这个状态序列并不能保证整体上是概率最大的。
- viterbi算法是解决隐马第三个问题(求观察序列最可能的标注序列)的一种实现方式。动态规划算法,递归关系和前向算法很类似。最后需要回溯,得到每个时刻的状态。
学习训练过程(学习问题)
- 如果除了观测序列还有隐状态序列,则采用极大似然估计。(监督学习)
- 如果只有观测序列,利用EM算法来训练HMM,被称为Baum-Welch(前向后向)算法。此时,状态作为隐变量。
最大熵马尔可夫模型MEMM - 判别式模型
条件随机场CRF - 判别式模型
CRF的序列标注问题中,我们要计算的是条件概率。
条件随机场是在给定的随机变量X(具体,对应观测序列o1,⋯,oi)条件下,随机变量Y(具体,对应隐状态序列i1,⋯,ii)的马尔科夫随机场。
| 概率无向图的联合概率分布可以在因子分解下表示为:P(Y | X)=\frac{1}{Z(x)} \prod_{c}\psi_{c}(Y_{c} | X ) = \frac{1}{Z(x)} \prod_{c} e^{\sum_{k}\lambda_{k}f_{k}(c,y | c,x)} = \frac{1}{Z(x)} e^{\sum_{c}\sum_{k}\lambda_{k}f_{k}(y_{i},y_{i-1},x,i)} |
| 而在线性链CRF示意图中,每一个(Ii∼Oi)对为一个最大团,即在上式中c = i。并且线性链CRF满足P(Ii | O,I1,⋯,In)=P(Ii | O,Ii−1,Ii+1)。 |
| 所以CRF的建模公式为:P(I | O)=\frac{1}{Z(O)} \prod_{i}\psi_{i}(I_{i} | O ) = \frac{1}{Z(O)} \prod_{i} e^{\sum_{k}\lambda_{k}f_{k}(O,I_{i-1},I_{i},i)} = \frac{1}{Z(O)} e^{\sum_{i}\sum_{k}\lambda_{k}f_{k}(O,I_{i-1},I_{i},i)} |
特征函数
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
- 句子s(就是我们要标注词性的句子)
- i,用来表示句子s中第i个单词
- l_i,表示要评分的标注序列给第i个单词标注的词性
- l_i-1,表示要评分的标注序列给第i-1个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
Note:这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。
模型运行过程
- 预定义特征函数
- 在给定的数据上训练模型
- 用确定的模型做序列标注问题或者序列求概率问题
学习训练过程
一套CRF由一套参数λ唯一确定。
序列标注问题
viterbi算法。
序列求概率问题
跟HMM举的例子一样的,也是分别去为每一批数据训练构建特定的CRF,然后根据序列在每个MEMM模型的不同得分概率,选择最高分数的模型为wanted类别。只是貌似很少看到拿CRF或者MEMM来做分类的,直接用网络模型不就完了不……
CRF++分析
定义模板
在CRF++下,应该是先定义特征模板,然后用模板自动批量产生大量的特征函数。每一条模板将在每一个token处生产若干个特征函数。
Unigram和Bigram模板分别生成CRF的状态特征函数s_{l}(y_{i},x,i)和转移特征函数t_{k}(y_{i-1},y_{i},x,i)。其中y_{i}是标签,x是观测序列,i是当前节点位置。每个函数还有一个权值,具体请参考CRF相关资料。
crf++模板定义里的%x[row,col],即是特征函数的参数x。
如下为10个模板:
[]里面的数字指的是某行、某列特征。[0,0]为本行字符,
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
Unigram类型
每一行模板生成一组状态特征函数,数量是L*N个,L是标签状态数,N是模板展开后的特征数,也就是训练文件中行数。
Bigram类型
与Unigram不同的是,Bigram类型模板生成的函数会多一个参数:上个节点的标签y_{i-1}。每行模板则会生成L*L*N个特征函数。
产生特征函数
U00 - U04的模板产生的是状态特征函数;U05 - U09的模板产生的是转移特征函数。
例如U02:%x[0,0],生成函数类似如下:
func1 = if (output = B and feature=U02:"北") return 1 else return 0
func2 = if (output = M and feature=U02:"北") return 1 else return 0
func3 = if (output = E and feature=U02:"北") return 1 else return 0
func4 = if (output = B and feature=U02:"京") return 1 else return 0
又如U01:%x[-1,0],训练后,该组函数权值反映了句子中上一个字对当前字的标签的影响。
Bigram类型模板生成的函数类似于:(多了一个上个节点的标签)
func1 = if (prev_output = B and output = B and feature=B01:"北") return 1 else return 0
求参
对以上特征以及初始权重进行迭代参数学习。
预测解码
LSTM+CRF
perspectively
LSTM已经可以胜任序列标注问题了,为每个token预测一个label(LSTM后面接:分类器);而CRF也是一样的,为每个token预测一个label。
但是,他们的预测机理是不同的。CRF是全局范围内统计归一化的条件状态转移概率矩阵,再预测出一条指定的sample的每个token的label;LSTM(RNNs,不区分here)是依靠神经网络的超强非线性拟合能力,在训练时将samples通过复杂到让你窒息的高阶高纬度异度空间的非线性变换,学习出一个模型,然后再预测出一条指定的sample的每个token的label。
LSTM+CRF
既然LSTM都OK了,为啥researchers搞一个LSTM+CRF的hybrid model?哈哈,因为a single LSTM预测出来的标注有问题啊!举个segmentation例子(BES; char level),plain LSTM 会搞出这样的结果:
input: "学习出一个模型,然后再预测出一条指定"
expected output: 学/B 习/E 出/S 一/B 个/E 模/B 型/E ,/S 然/B 后/E 再/E 预/B 测/E ……
real output: 学/B 习/E 出/S 一/B 个/B 模/B 型/E ,/S 然/B 后/B 再/E 预/B 测/E ……
看到不,用LSTM,整体的预测accuracy是不错indeed, 但是会出现上述的错误:在B之后再来一个B。这个错误在CRF中是不存在的,因为CRF的特征函数的存在就是为了对given序列观察学习各种特征(n-gram,窗口),这些特征就是在限定窗口size下的各种词之间的关系。然后一般都会学到这样的一条规律(特征):B后面接E,不会出现E。这个限定特征会使得CRF的预测结果不出现上述例子的错误。当然了,CRF还能学到更多的限定特征,那越多越好啊!好了,那就把CRF接到LSTM上面,把LSTM在timestep上把每一个hiddenstate的tensor输入给CRF,让LSTM负责在CRF的特征限定下,依照新的lossfunction,学习出一套新的非线性变换空间。最后,不用说,结果还真是好多了呢。
总结
总体对比
应该看到了熟悉的图了,现在看这个图的话,应该可以很清楚地get到他所表达的含义了。这张图的内容正是按照生成式&判别式来区分的,NB在sequence建模下拓展到了HMM;LR在sequence建模下拓展到了CRF。
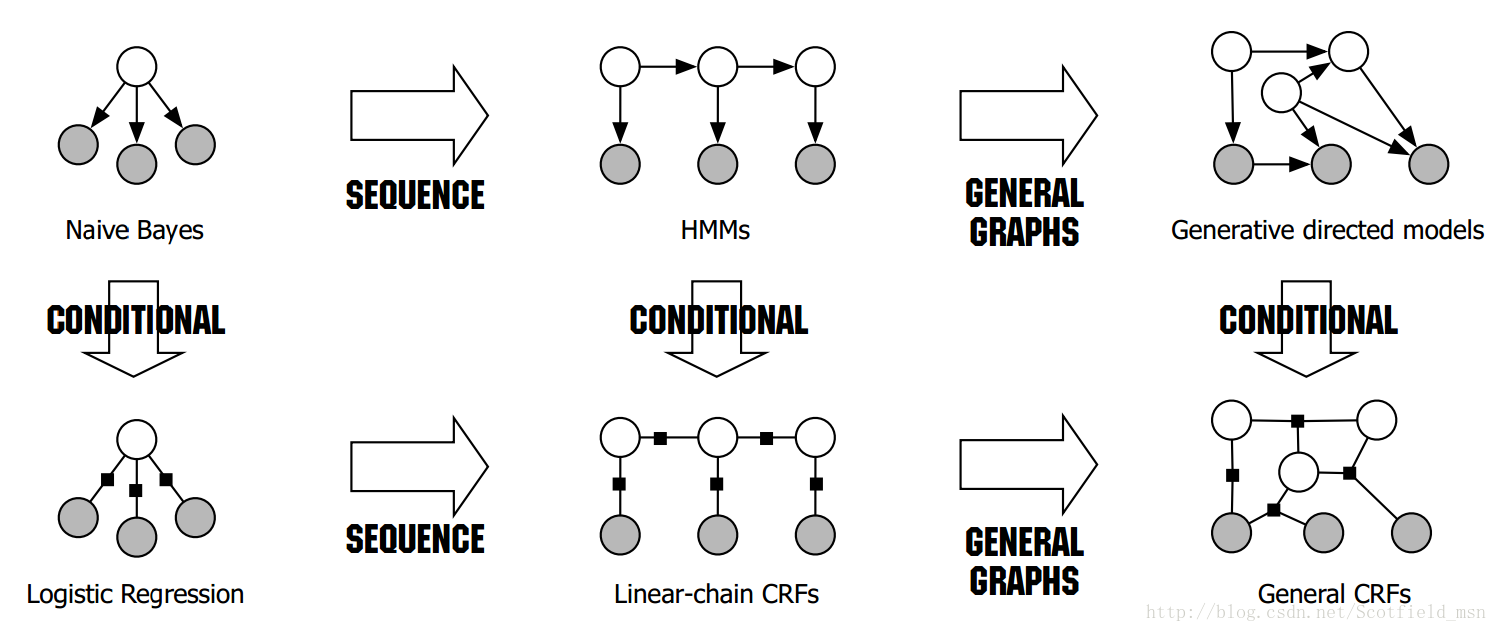
HMM vs. MEMM vs. CRF
- HMM -> MEMM:HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关。但实际上序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。MEMM解决了HMM输出独立性假设的问题。因为HMM只限定在了观测与状态之间的依赖,而MEMM引入自定义特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂依赖。
- MEMM -> CRF:CRF不仅解决了HMM输出独立性假设的问题,还解决了MEMM的标注偏置问题,MEMM容易陷入局部最优是因为只在局部做归一化,而CRF统计了全局概率,在做归一化时考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。使得序列标注的解码变得最优解。
- HMM、MEMM属于有向图,所以考虑了x与y的影响,但没讲x当做整体考虑进去(这点问题应该只有HMM)。CRF属于无向图,没有这种依赖性,克服此问题。
参考
理解Graph Theory——有向图、无向图(重要!!!)
HMM是典型的有向图模型,CRF是典型的无向图模型。MEMM是有向图吗?MEMM的概率分解,为啥和典型的有向图或无向图都不同呢?
如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?
An Introduction to Conditional Random Fields
97.5%准确率的深度学习中文分词(字嵌入+Bi-LSTM+CRF)
github-BiLSTM-CRF joint model for tasks like sequence labeling
(好资料)CRF Layer on the Top of BiLSTM (BiLSTM-CRF)(解释crf层的工作原理)