RNN(Simple RNN/Vanilla RNN)
为什么要有RNN?
当人们在思考的时候,不会从头开始,而是保留之前思考的一些结果来为现在的决策提供支持。同时,我们会根据上下文的信息来理解一句话的含义。但是传统的神经网络并不能实现这个功能,这就是其一大缺陷。而RNN的结构的最大特点是神经元的某些输出可作为其输入再次传输到神经元中,因此可以利用之前的信息。
DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。而对于这类问题,RNN比较擅长。
RNN的网络结构
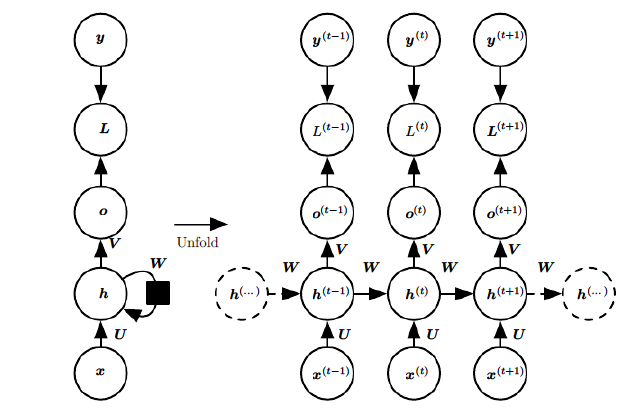
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。
这幅图描述了在序列索引号t附近RNN的模型。其中
- x^{(t)}表示在t时刻训练样本的输入,$ x^{(t-1)}和$ x^{(t+1)}表示在t-1时刻和t+1时刻训练样本的输入。
- h^{(t)}表示在t时刻模型的隐藏状态,它由x^{(t)}和h^{(t-1)}共同决定。
- o^{(t)}表示在t时刻模型的输出,它仅仅由模型当前的隐藏状态h^{(t)}来决定。
- y^{(t)}表示在t时刻模型的真实输出。
- L^{(t)}表示在t时刻模型的损失函数。
- U,W和V是模型的线性关系参数,在整个RNN网络中是共享的。这个是和DNN的不同之处,正是由于共享,体现了RNN模型的“循环反馈”的思想。
RNN的前向传播算法
任一时刻t,隐藏状态h^{(t)}由x^{(t)}和h^{(t-1)}共同决定。
h^{(t)} = \sigma(z^{(t)}) = \sigma(Ux^{(t)} + Wh^{(t-1)} +b )
其中\sigma为RNN的激活函数,一般为tanh, b为线性关系的偏倚。
任一时刻t,模型的输出o^{(t)}仅仅由h^{(t)}来决定。
o^{(t)} = Vh^{(t)} +c
任一时刻t,模型的预测输出为:
\hat{y}^{(t)} = \sigma(o^{(t)})
通常由于RNN是识别类的分类模型,所以上面这个激活函数一般是softmax。
RNN的反向传播算法
RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮的迭代,得到合适的RNN模型参数U,W,V,b,c。
但由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time)。
重点是这里的BPTT和DNN也有很大的不同点,即这里所有的U,W,V,b,c在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
门机制
LSTM
为什么要有LSTM?
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失的问题,当序列很长的时候问题尤其严重。
RNN虽然被设计成可以处理整个时间序列信息,但其记忆最深的还是最后输入的一些信号,而更早之前的信号强度越来越低,最后仅仅起到辅助作用。
LSTM的网络结构
RNN和LSTM的网络结构的对比:
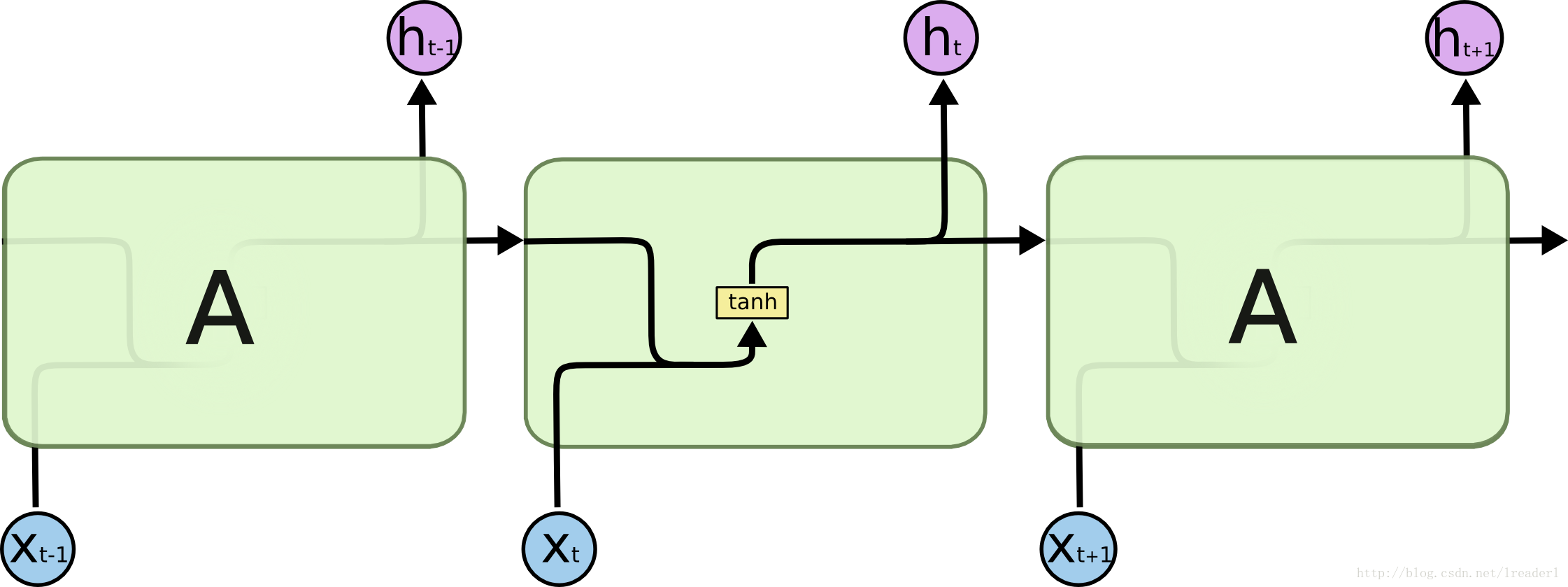
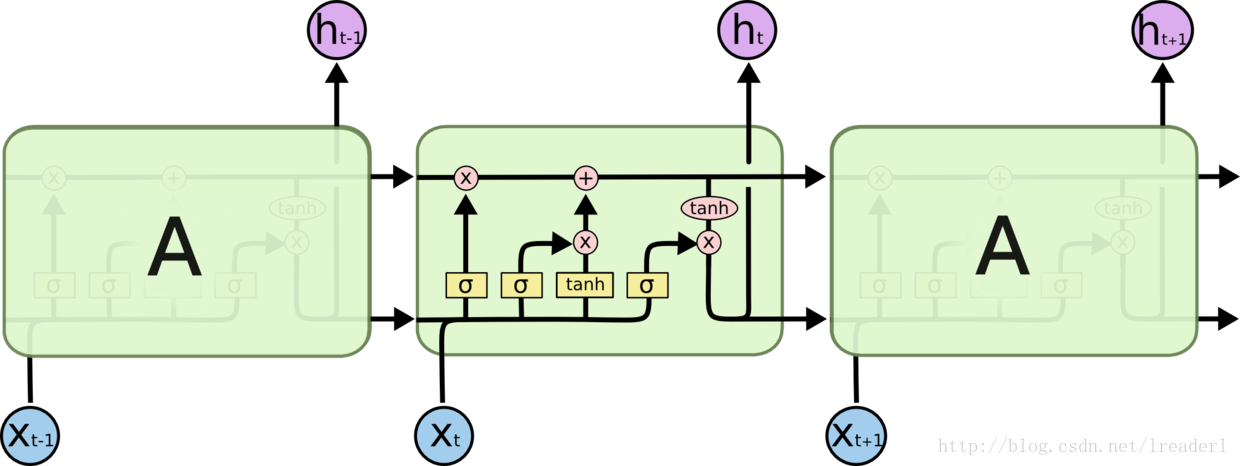
由以上两幅图可以看出来,RNN只有一个神经元和一个tanh层进行重复的学习。但是在长环境中相关的信息和预测的词之间的间隔可以是非常长的,理论上RNN也可以学习到这些知识,但是实践中RNN并不能学到这些知识。
标准LSTM模型是一种特殊的RNN类型,在每一个重复的模块中有四个特殊的结构,以一种特殊的方式进行交互。黄色的矩阵即为学习到的神经网络层。LSTM模型的核心思想是“细胞状态”。
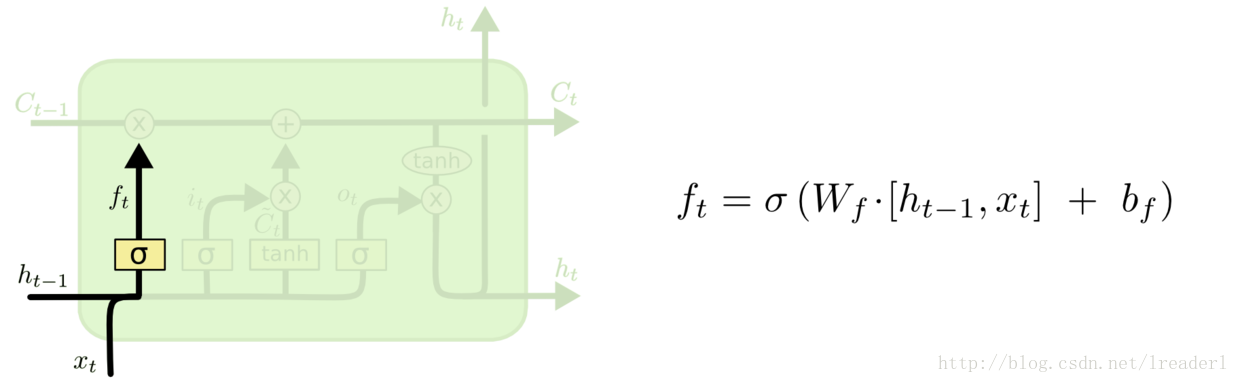
遗忘门: 第一步是决定我们从“细胞”中丢弃什么信息,这个操作由一个忘记门层来完成。该层读取当前输入x和前神经元信息h,由ft来决定丢弃的信息。输出结果1表示“完全保留”,0 表示“完全舍弃”。
输入门: 第二步是确定细胞状态所存放的新信息,这一步由两层组成。sigmoid层作为“输入门层”,决定我们将要更新的值i;tanh层来创建一个新的候选值向量~Ct加入到状态中。在语言模型的例子中,我们希望增加新的主语到细胞状态中,来替代旧的需要忘记的主语。
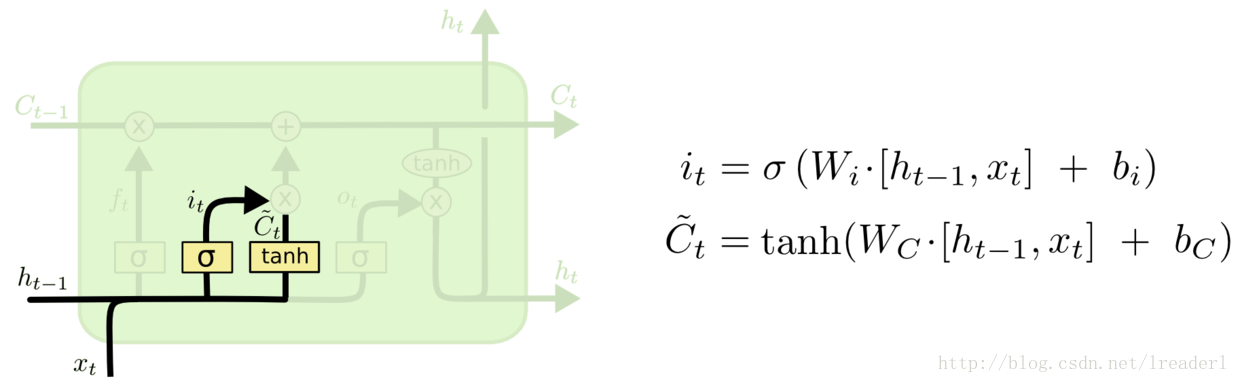
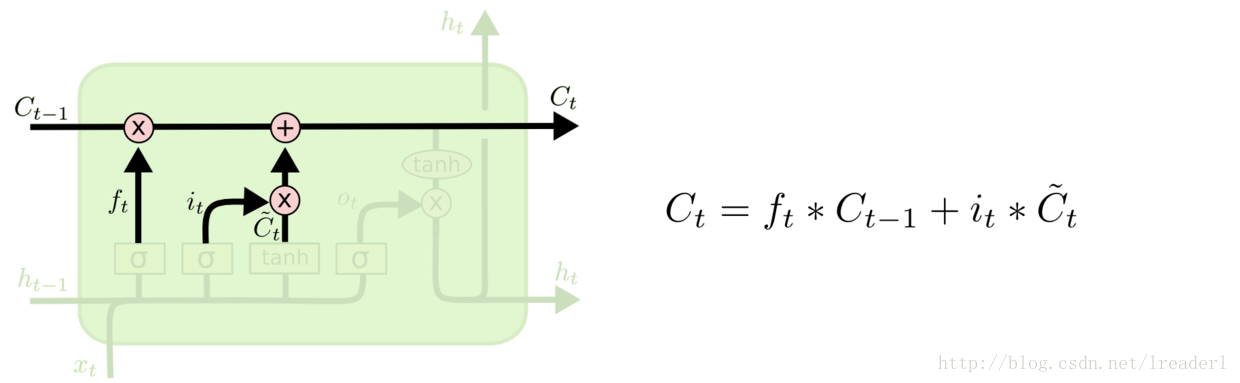
第三步就是更新旧细胞的状态,将Ct-1更新为Ct。我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it * ~Ct,这就是新的候选值。
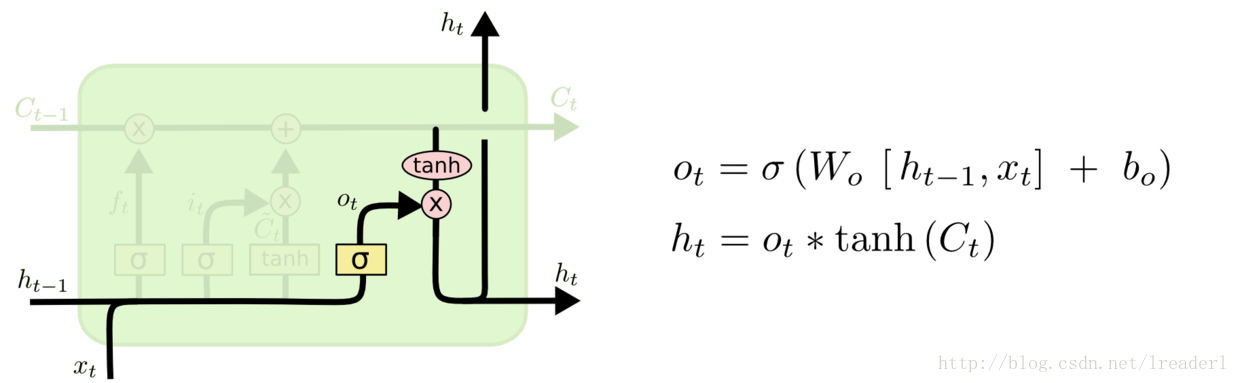
输出门:
最后一步就是确定输出了,这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。我们运行一个sigmoid层来确定细胞状态的哪个部分将输出出去。
GRU
为什么要有GRU?
GRU即Gated Recurrent Unit。GRU保持了LSTM的效果同时又使结构更加简单,所以它也非常流行。
GRU的网络结构

而GRU模型如上图所示,相比LSTM有三个门它只有两个门了,分别为更新门和重置门,即图中的zt和rt。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
r_t=\sigma(W_r\cdot[h_{t-1},x_t])
z_t=\sigma(W_z\cdot[h_{t-1},x_t])
{\tilde{h}}_t=\tanh(W_{\tilde{h}} \cdot[r_t\ast h_{t-1},x_t])
h_t=(1-z_t)\ast h_{t-1}+z_t \ast \tilde{h}_t
y_t = \sigma(W_o \cdot h_t)
GCNN
《Language Modeling with Gated Convolutional Networks》阅读笔记
目前语言模型主要基于RNN,文章提出了一个新颖的语言模型,仿照LSTM中的门限机制,利用多层的CNN结构,每层CNN都加上一个输出门限。文中提出的GLU模型在两个常用数据集上的测试效果超过了目前循环模型,并且速度更快。
文中具体提出了GTU和GLU两种模型,两个模型整体类似,主要是激活函数不一样。GLU的激活函数是线性的;GTU的激活函数是tanh,是非线性的。作者从梯度的角度分析了GLU比GTU更优。
这篇文章提出了基于卷积神经网络和门限机制的深度学习模型,将其运用到语言模型中,取得了比循环神经网络模型好的效果,同时由于卷积神经网络局部性的特点使得其可以在词序列中中进行并行训练,提高了处理的速度,同时引人门限机制,减缓梯度消失,加快了模型的收敛速度。通过叠加多层来学习词序列的前后依赖关系,使得其在长文本WikiText-103语言模型的学习中也取得不错的效果。
Tree-LSTM
哈工大车万翔:自然语言处理中的深度学习模型是否依赖于树结构?
本文作者总结出下面的结论。
需要树形结构:
- 需要长距离的语义依存信息的任务(例如上面的语义关系分类任务)Semantic relation extraction。
- 输入为长序列,即复杂任务,且在片段有足够的标注信息的任务(例如句子级别的Stanford情感树库分类任务),此外,实验中作者还将这个任务先通过标点符号进行了切分,每个子片段使用一个双向的序列模型,然后总的再使用一个单向的序列模型得到的结果比树形结构的效果更好一些。
不需要树形结构:
- 长序列并且没有足够的片段标注任务(例如上面的二元情感分类,Q-A Matching任务)。
- 简单任务(例如短语级别的情感分类和Discourse分析任务),每个输入片段都很短,句法分析可能没有改变输入的顺序。
LSTM(Long Short Term Memory)和RNN(Recurrent)教程收集
《Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks》阅读笔记
输入门、遗忘门、输出门的参数都是共享的。
LSTM变体:peephole connection
GridLSTM
https://arxiv.org/abs/1507.01526
Stacked LSTM
Nested LSTM
Minimal Gated Unit 2016
https://arxiv.org/abs/1603.09420
RAN 2017
这篇文章简化了一下LSTM,扔掉了输出门,每一步的candidate cell state只考虑当前步的输入而不管历史信息。最后发现效果跟原来的LSTM差不多,参数却少了很多。于是认为非线性不那么重要,门机制才重要。
这篇论文还把GRU表示成了一种奇怪的、类似于LSTM的形式,有利于比较LSTM和GRU的异同,并且认为RAN同时是LSTM和GRU的简化版。
SRU(Simple Recurrent Unit 2017)(重要)
爆款论文提出简单循环单元SRU:像CNN一样快速训练RNN(附开源代码)
如何评价新提出的RNN变种SRU? 里面也有和QRNN的对比
| [干货 | 解读加实战:爆款论文 SRU 在对话生成上的效果](https://mp.weixin.qq.com/s/i-EWyn208OQRBvZz2aIu5g) |
从SRU小小的学术争议,可以学到什么?关于SRU简单循环单元,David 9 有几点想说
Simple Recurrent Unit For Sentence Classification
QRNN/Quasi-RNN 2016 (重要)
https://arxiv.org/abs/1611.01576
QRNN在公司业务中效果很好
SRNN
比RNN快136倍!上交大提出SRNN,现在RNN也能做并行计算了
Skim-RNN
《Neural Speed Reading via Skim-RNN》阅读笔记
persistent RNN(baidu出品,重要)
RevRnn
ConvLSTM: CNN和RNN的结合(重要)
引入卷积运算的RNN,架构总体上还是RNN。
TrellisNet(重要)
本文提出了一种新颖的架构——网格网络(TrellisNet)。网格网络的结构融合了CNN和RNN,因此可以直接吸收许多为CNN和RNN设计的技术,从而在多项序列建模问题上战胜了当前最先进的CNN、RNN、自注意力模型。
ConvLSTM更多的是引入卷积运算的RNN,架构总体上还是RNN。TrellisNet中,CNN、RNN的联系深入到架构层面。
TrellisNet拥有着RNN和CNN的优点,也可以用双方的现有技巧来弥补两个模型各自的缺点;因此RNN和CNN有比大多数人认为的更紧密的关联。
解释
特点
这类RNN Cell大家应该很熟悉了,其主要特点是用门控制信息流动,隐层状态采用加性更新,不做非线性变换。
Written Memories: Understanding, Deriving and Extending the LSTM
设计初衷
上述文章讲了LSTM设计的初衷和原则、然后根据这些原则推导出了GRU的设计。但上述文章认为认为LSTM里的读写顺序和状态分裂为(c, h)等设计很奇怪(文中叫 LSTM hiccup)。下面文章解释和完善了这种设计。
效果
理论上,各个门的值应该在[0, 1]之间。但是如果你真正训过一些表现良好的网络并且查看过门的值,就会发现很多时候门的值都是非常接近0或者1的,而类似于0.2/0.5这样的中间值很少。从直觉上我们希望门是二元的,控制信息流动的通和断,事实上训练良好的门也确实能达到这种效果。
加入门机制可以解决普通 RNN 的梯度消失的问题。
更重要的是,门可以控制信息变形(information morphing)和选择性(selectivity)。
- 选择性体现在,想让信息流动的时候的就让它流动,不想让它流动的时候就关掉。
- 信息变形体现在,模型状态在跨时间步时不存在非线性变换,而是加性的。
跨尺度连接
CW-RNN: Clockwise RNN
普通RNN都是隐层从前一个时间步连接到当前时间步。而CW-RNN把隐层分成很多组,每组有不同的循环周期,有的周期是1(和普通RNN一样),有的周期更长(例如从前两个时间步连接到当前时间步,不同周期的cell之间也有一些连接。这样一来,距离较远的某个依赖关系就可以通过周期较长的cell少数几次循环访问到,从而网络层数不太深,更容易学到。
Dilated RNN
和CW-RNN类似,只是CW-RNN是在同一个隐层内部分组,Dilated RNN是在不同的层分组:最下面的隐层每个时间步都循环,较高的隐层循环周期更长些,从而有效感受野更大。
NARX RNN: Nonlinear Auto-Regressive eXogenous RNN
类此以上两种方法,但前面的方法是把隐层单元分组,有的单元单步循环,有的多步循环;而这种方法是让每个隐层单元都在不同尺度上循环,例如某个隐层状态直接依赖于它的前一个、前两个、直到前 n-1 个隐层状态
如果说普通的 RNN 是一阶递推式,这种就是 n 阶递推式
TKRNN: Temporal Kernel RNN
类似 NARX RNN,只是把 n 阶递推式写成了特殊的、便于参数共享的形式,从而计算起来更快。
解释
既然学习长期依赖很难,那就手动把依赖的步数缩短,然后学习短期依赖就可以了。思想有点儿类似于 ResNet 中的 skip-connection(但是跨越多个时间步的连接用的不是单位阵,而是需要学习的稠密矩阵),使得模型输出层可以看到之前不同时间步的信息,进而达到类似模型集成的效果。
特殊初始化(及其维持)
IRNN: Identity Recurrent Neural Networks
np-RNN: normalized-positive definite RNN
RIN: Recurrent Identity Network
Unitary-RNN
IndRNN
singular value clipping
SCRNN:Structurally Constrained Recurrent Neural Network
解释
特殊初始化(及其维持)大致有三种方法:(近似)恒等映射、正交化、参数范围控制。
其他
Statistical Recurrent Unit
Fourier Recurrent Unit
论文
An Empirical Exploration of Recurrent Network Architectures
通过实验的方法证实,output gate 一般用处不大:”We discovered that the input gate is important, that the output gate is unimportant, and that the forget gate is extremely significant on all problems except language modelling”。
参考
(没看)从信息隐匿的角度谈 LSTM:从 Stack 到 Nest
Written Memories: Understanding, Deriving and Extending the LSTM